Let’s say you have two or more text files that you want to compare. When comparing files, it is usually one of two things that you are trying to achieve…1) Find all common lines in both files or all files and/or 2) Find all differing lines in both files.
It all depends on how closely related the two files are. If most of the lines (say, more than 50%) in the files are the same then you probably are looking for all differing lines and vice-versa.
There are two related Linux commands that lets you compare files from command line. These commands lets you find either the common lines or the differing lines: comm and diff. diff is the more popular of the two, as the most common use case is to find differing lines (I think!). Also, it is more feature rich of the two commands.
In this post, we will look at comm command in detail as we are trying to find common or similar lines in files. Straight out of the box, the comm command has some (mainly, two) limitations: It works only with pre-sorted files and it works with only two files.
Sorted Files
If you have two files that are already sorted, then you can use the comm command directly on these files. Using the command without any options as shown below will produce a three column output, the first column shows lines that are unique to file1, the second column are lines that are unique to file2 and the third column shows lines that are common to both files. Here, file1 and file2 are example file names.
bash$ comm file1 file2
So, if you like to see only lines that are common to both files, then you can suppress the printing of columns 1 and 2 as shown in the example below.
bash$ comm -12 file1 file2
The comm command by default checks that the files are in sorted order. You can force this check using the command line option –check-order. You can also turn this check off using the option –nocheck-order.
bash$ comm --nocheck-order -12 file1 file2
This option (–nocheck-order) is useful when you want comm to treat the input files as sorted. This can be useful when comparing certain files, such as log files. In this case, you want the command to consider lines to be same only if it occurs in the same place in the file. Beware though that it can get a little tricky to interpret the results.
Un-sorted Files
If your files are not sorted, then obviously the first option is to sort the files and then run the comm command. The Linux command sort will allow you to sort text files. The following set of three commands will allow you to sort and find common lines.
bash$ sort file1 > file1-sorted
bash$ sort file2 > file2-sorted
bash$ comm -12 file1-sorted file2-sorted
Being Linux, you can easily combine the above three commands to a single line. This will also take away the hassle of having to create intermediate files.
bash$ comm -12 <(sort file1) <(sort file2)
Well, comm is not the only command that can be used to find common lines. You can use a combination of cat, sort and uniq to achieve the same result. To start with, we can do something like this…
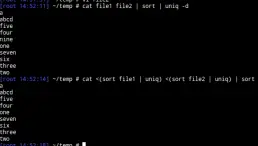
bash$ cat file1 file2 | sort | uniq -d
The -d option in uniq command is important in this context because that specifies that it should show only repeated or duplicate lines. Without the -d option, it will print the unique lines whether duplicated or not which is not what you want.
However, there is a small caveat with this approach. It assumes that each line is unique with in the file. If the same line occurs twice or more with in the same file (say, file1) then it will be printed as a common line which is not correct.
The solution is to sort and remove duplicate of each individual file before merging them for the final sort and unique check. Remember that for large files, this might not be so efficient…
bash$ cat <(sort file1 | uniq) <(sort file2 | uniq) | sort | uniq -d
More than two files
The comm command and the commands above works with two files. If you want to compare more than two files, then comm command is not much help. However the command used in the above section, the one with cat, sort and uniq can be pretty scalable.
bash$ cat <(sort file1 | uniq) <(sort file2 | uniq) <(sort file3 | uniq) <(sort file4 | uniq) | sort | uniq -d
The command above can sort and compare 4 different files. However, the efficiency can depend very much on the size of your input files. It can work for small files (maybe around 1000 lines or so). Also, if you find yourself using this often then you can convert this into a shell script that takes the file names as arguments. I will leave that as a project for you…